Agora é hora de começar a trabalhar com os outros dataframes para podermos avançar na análise de dados.

Lembra que no nosso post ” Hora de colocar a mão na massa” a gente começou a trabalhar com o dataframe do site da covid.saude. Agora é hora de fazer umas coisinhas nele.Vamos pela teoria de Jack (por partes…rsss).
Primeiro abrir os 3 dataframes;
df1 = pd.read_csv(‘/content/sample_data/Projeto/HIST_PAINEL_COVIDBR_2020_Parte1_25mai2021.csv’,sep=’;’)
df2 = pd.read_csv(‘/content/sample_data/Projeto/HIST_PAINEL_COVIDBR_2020_Parte2_25mai2021.csv’,sep=’;’)
df3 = pd.read_csv(‘/content/sample_data/Projeto/HIST_PAINEL_COVIDBR_Parte3_25mai2021.csv’,sep=’;’)
Segundo junta os dataframes em um só;
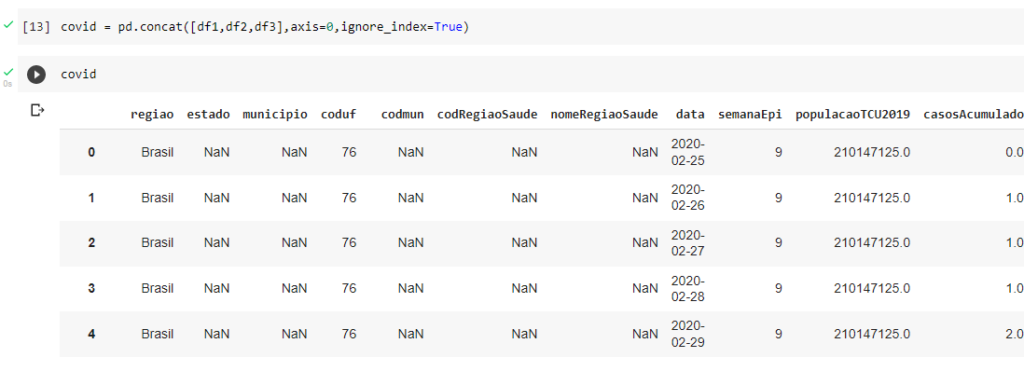
covid = pd.concat([df1,df2,df3],axis=0,ignore_index=True)
Terceiro tira o que não vamos querer usar;
Vamos visualizar as colunas que este dataframe têm,
covid.columns
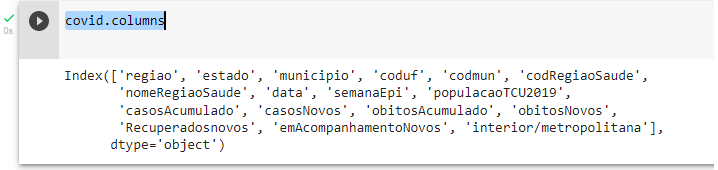
Agora tirar as colunas que eu não quero
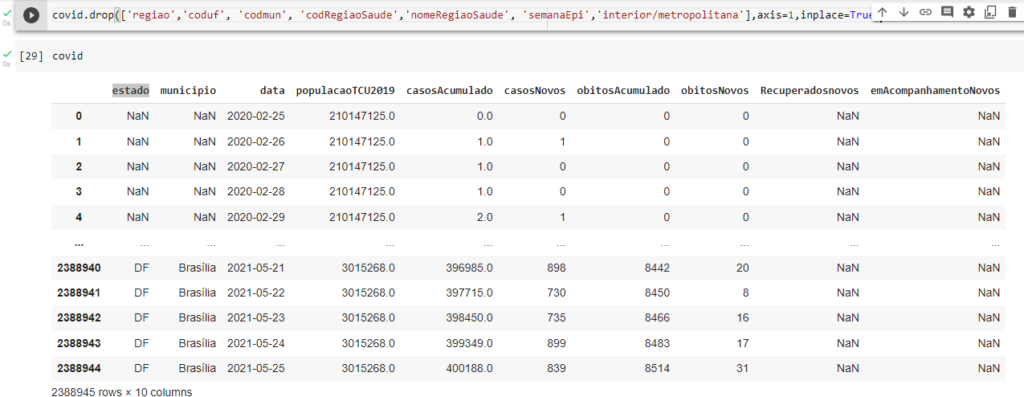
covid.drop([‘regiao’,’coduf’, ‘codmun’, ‘codRegiaoSaude’,’nomeRegiaoSaude’, ‘semanaEpi’,’interior/metropolitana’],axis=1,inplace=True)
Vamos vê como ficou até agora.
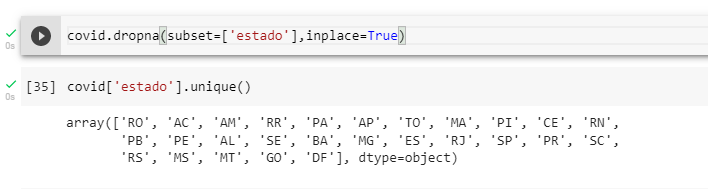
O NAn na coluna “estado”, vamos apagar com o comando “dropna” usando o parametro “subset” que nos permite informar o nome da coluna.
covid.dropna(subset=[‘estado’],inplace=True)
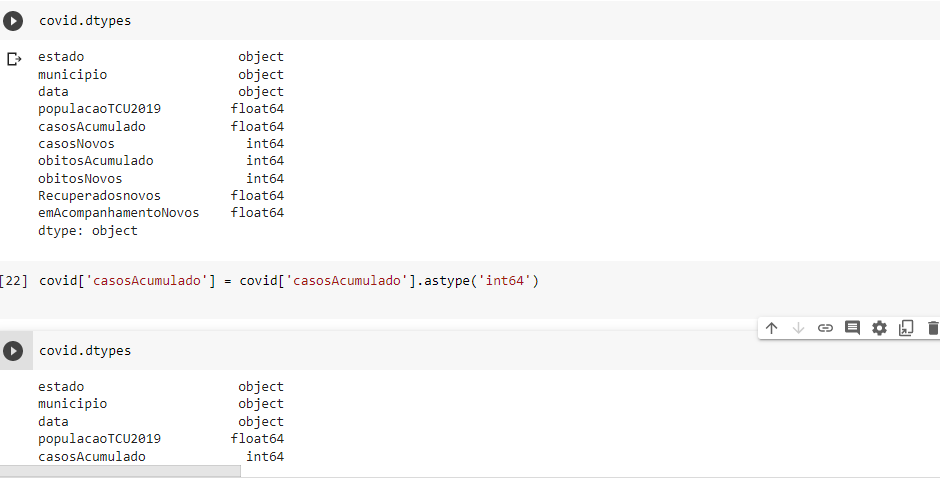
Vou mudar o tipo do dado da coluna ‘ casosAcumulados’ para int64.
Beleza até agora tudo ok, vou deixa este database parado por um momento e vou carregar o próximo.
Agora vou carregar o database com os índices que o IBGE possuiu sobre educacional, renda per capita, densidade demográfica do site https://www.ibge.gov.br/cidades-e-estados/ba.html? nele você click em exportar e escolhe todas as unidades federativas e qual o formato que você deseja os dados.
Vamos abrir ele, como os dados estão no meu google drive vou passa o caminho e já dar um nome para o database e o colab vai conseguir abrir.
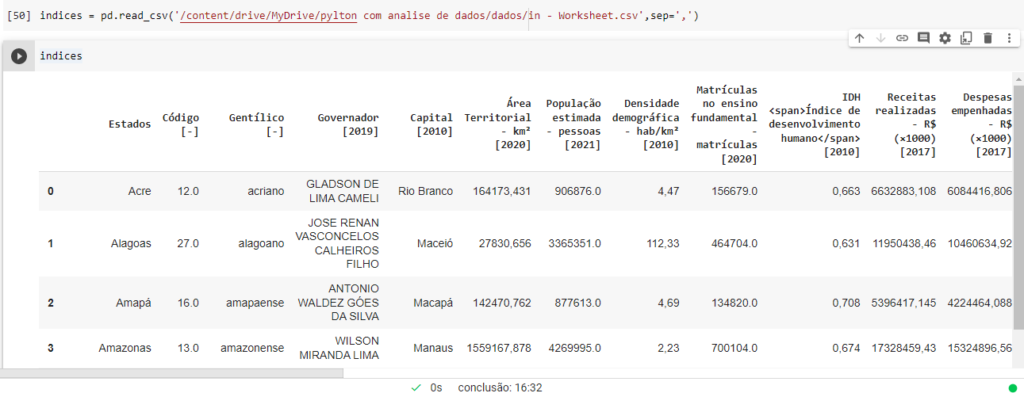
Agora hora de fazer o drop nas colunas que não quero.
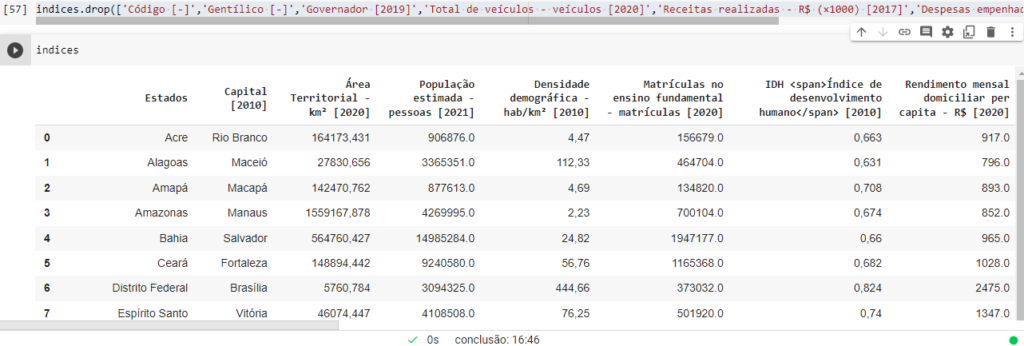
indices.drop([‘Código [-]’,’Gentílico [-]’,’Governador [2019]’,’Total de veículos – veículos [2020]’,’Receitas realizadas – R$ (×1000) [2017]’,’Despesas empenhadas – R$ (×1000) [2017]’],axis=1,inplace=True)
Maravilha, agora vamos tirar a legenda que vem do IBGE que esta nesta database e quando a gente vai visualizar fica feia, mas não se preocupe o database com esta legenda vai esta no github, eu vou tirar daqui para ficar bonito ok , vamos usar o comando:
indices.dropna( axis=0, inplace=True )
Feito ele vai aparace para você so os 27 unidades da federação.
Agora é pensar quais dados de quais database a gente vai carregar para nossa database final, logo muita calma nesta hora.
Beijos, Maga.😘