
Nem sempre pegamos um dataframe todo arrumadinho, mas para estes casos de caos podemos contar com o pandas para nos ajudar nestas horas de desespero.
Então vamos arrumar os dados para concatenar os 27 estados da federação. Aí Deus!! Começou a hora mais linda 😭 só que não.

Chamamos o dataframe do estado e no comando colocamos a coluna, tudo certinho para fazer o replace ( alteração do nome). A telinha da raiva aparece me falando toda prosa que tem erro: ” que não existe a coluna ‘ Estado ‘. Como assim não existe.
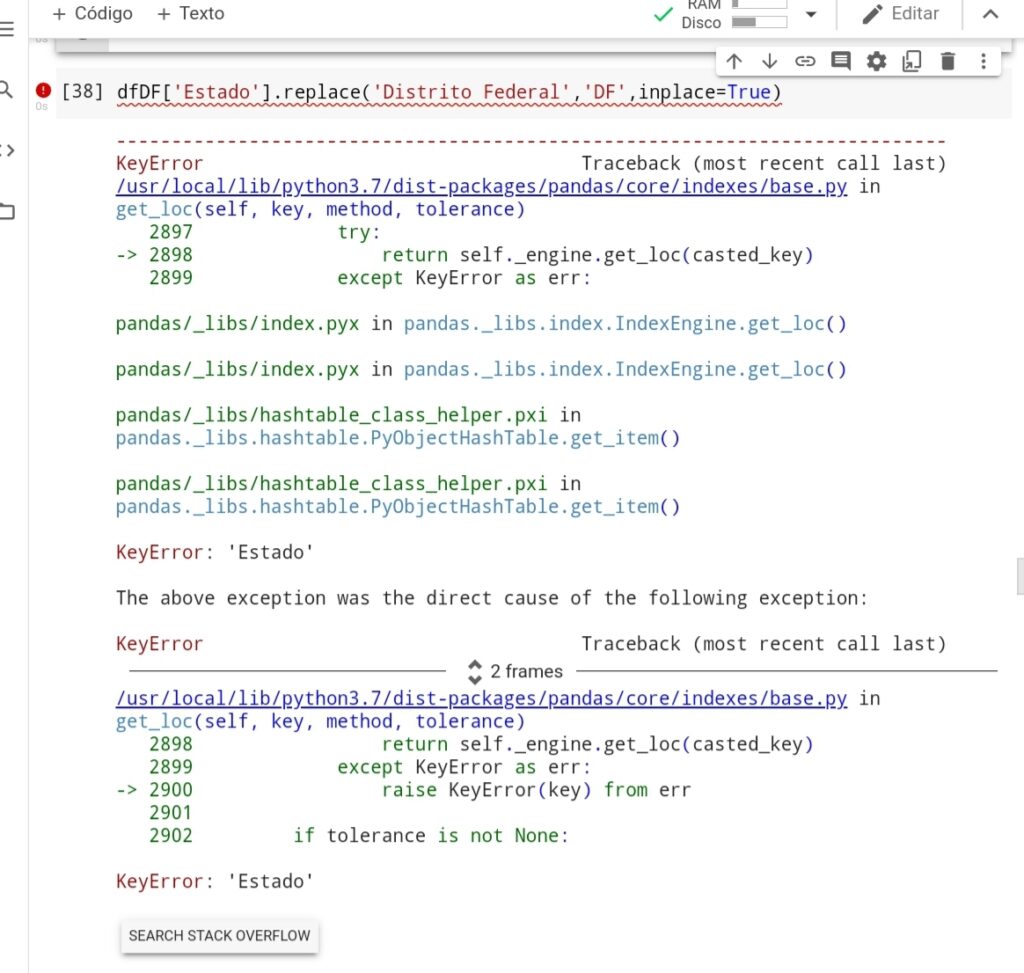
Pois é o arquivo CSV deste estado a coluna citada esta faltando o ‘ a’ , e como você sabe é só chamar a base de dados e olhar a coluna. Esta tem o nome de dfDF, dataframe do estado do DF – Distrito Federal.
Beleza e então como corrigimos? Existem duas saídas ou você vai no arquivo CSV e acrescenta a vogal ou você aprende um jeito novo com o pandas. Qual você escolhe… aprender mais comandos, eba !
Comando rename de novo na área.
https://pandas.pydata.org/pandas-docs/version/0.21/generated/pandas.DataFrame.rename.html
dfDF.rename(columns{‘Estdo’:’Estado’},inplace=True
Legenda do comando;
dfDF = nome do dataframe
rename = comando pandas para renomear
columns{‘Estdo’:’Estado’}, = coluna desejada entre chaves primeiro como está a coluna depois como deve ficar a coluna
Inplace=True = para fazer a alteração no dataframe .
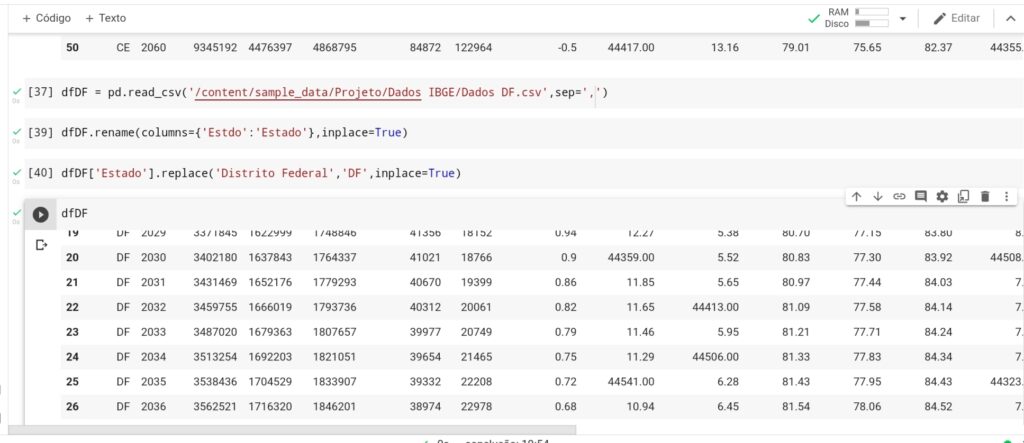
Tem outro estado com um espaço após o nome da coluna então usei novamente o rename, mas você acha que foi só isso, o Deus que nada, no Tocantis percebi que a quantidade de linhas estava superior aos demais estados.
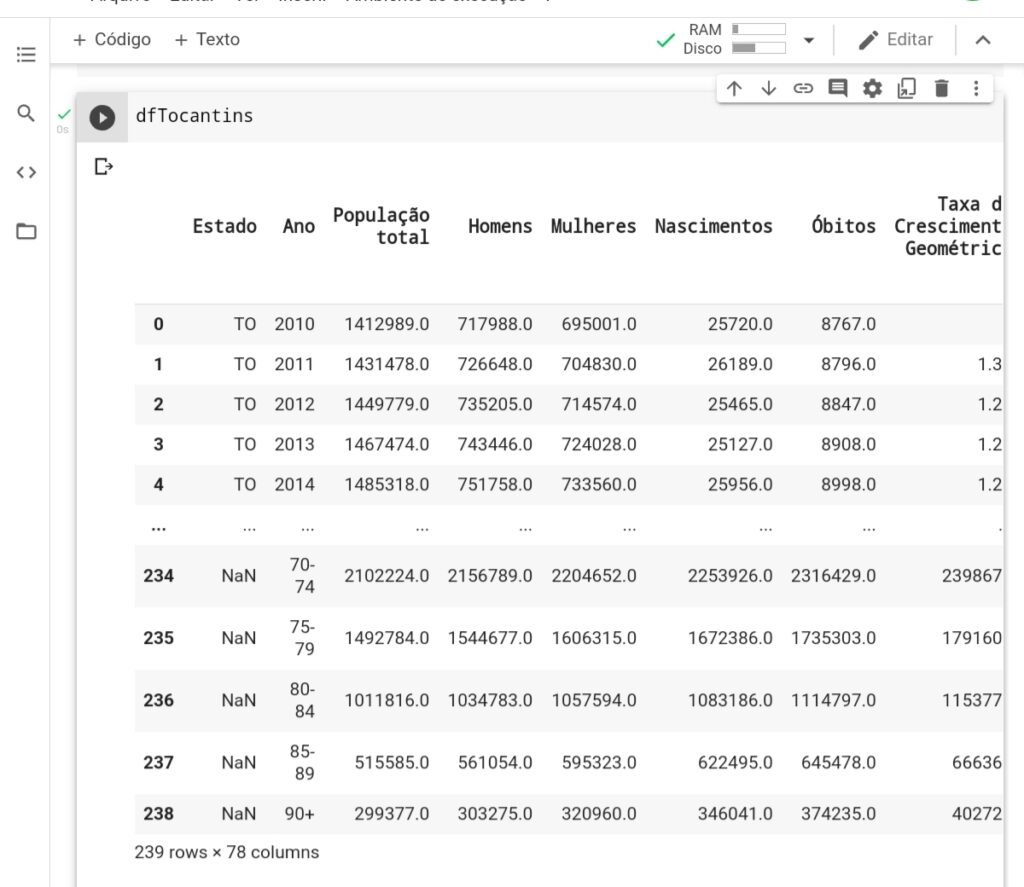
Ok verificado o dataframa vamos visualizar então os índices com problema com o comando loc.
Comando novo “drop” e nele existe o “dropna” que deixa apagar no dataframe tanto linhas como colunas ou ambos que estejam com o “NaN”, vamos só apagar linhas então axis=0.
dfTocantins.dropna( axis=0, inplace=True )
Vamos verificar agora com o comando value_counts quais são os valores da coluna “Ano”.

https://pandas.pydata.org/docs/reference/api/pandas.Series.value_counts.html
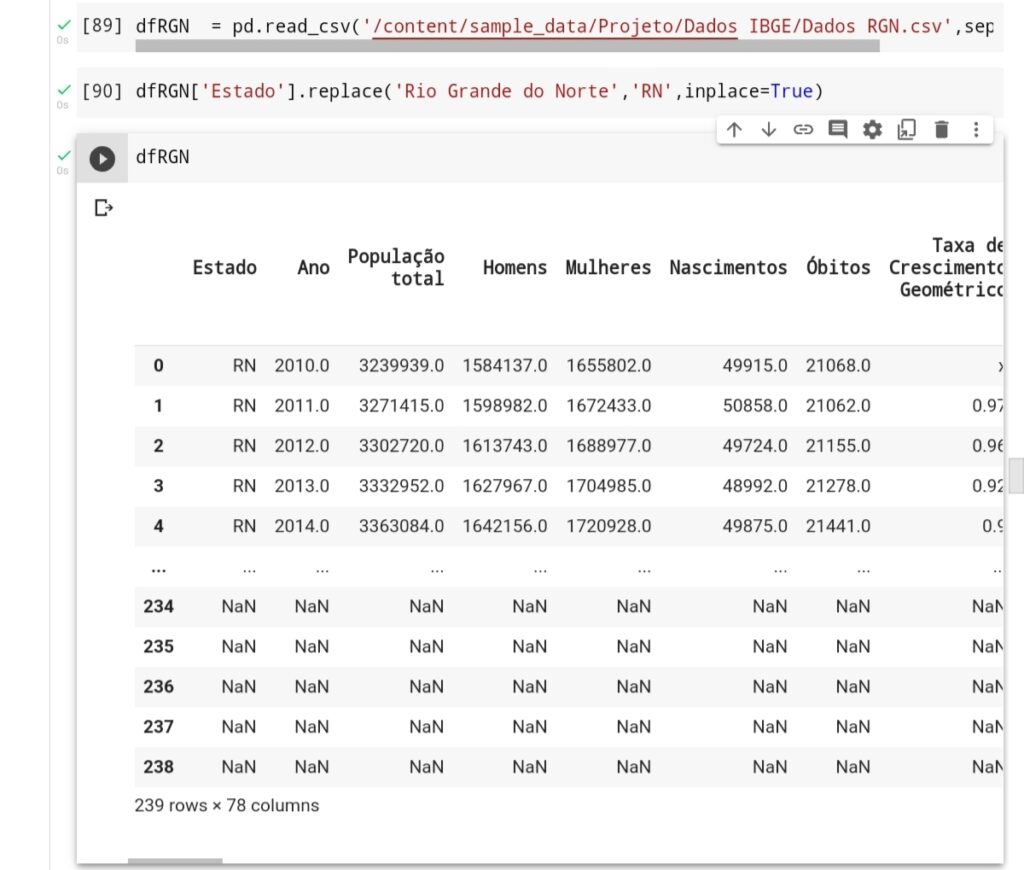
Acabou né? Você se pergunta dai e a reposta é … não, tem mais coisa para arrumar, percebi que tinha um estado que na coluna “Ano” estava 5 digitos e um ponto no caso era um tipo float. Logo precisamos arrumar para que o ano fique com 4 dígitos sendo um número inteiro.
Comando “dtypes” para informar o tipo de cada coluna do dataframe.
Isso aí, arrumamos os dataframes e aprendemos comandos novos.

Beijos, Maga.😘