E estamos de volta com mais alguns conhecimentos, uhuu!!!
Então vou adicionar na pasta projeto no Colab mais dataframes, agora são os dados de cada estado da federação retirados do site do IBGE.

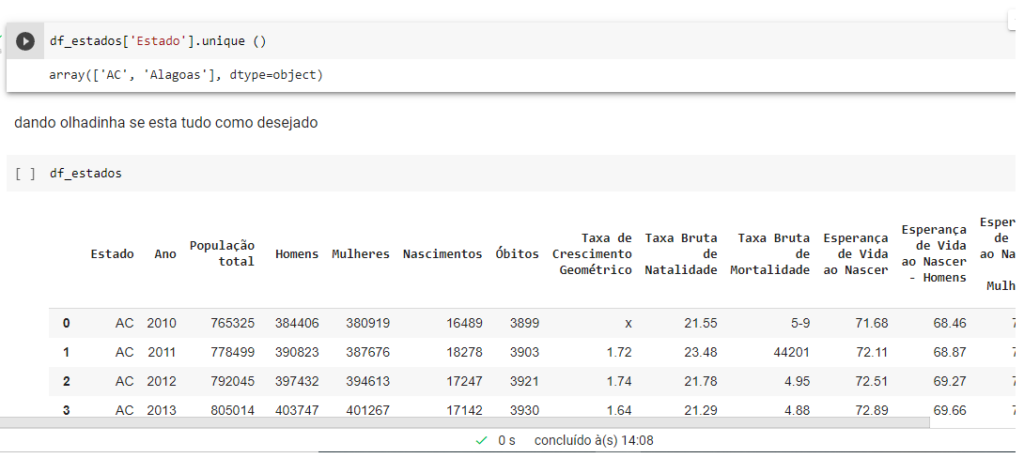
Vamos verificar uma das dataframes, peguei de exemplo o Acre.
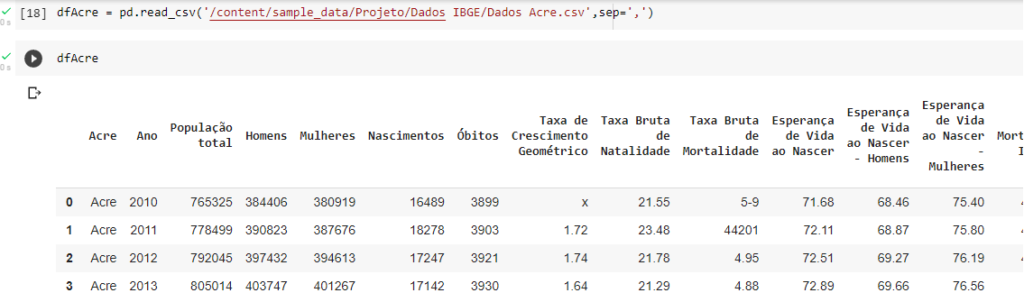
Ok dataframe está com todas as informações que o IBGE disponibiliza com estimativas até o ano de 2060, esta brincando ou quer mais.
Agora é hora de fazer algumas alterações
Neste existe a coluna Acre, e em suas linhas o nome por extenso do estado. Pra deixa tudo padrão vamos trocar o nome da coluna de Acre para Estado e nas linhas em vez do nome do estado por extenso vamos colocar sigla dele.
Primeiro comando para trocarmos o nome da coluna.
dfAcre.rename(columns={‘Acre’:’Estado’},inplace=True)
Legenda
dfAcre = nome do dataframe que tem os dados do Acre.
Rename = comando do pandas que permite fazer alteração dos nomes.
Columns = parâmetro do que você deseja alterar neste caso coluna
{‘Acre’:’Estado’} = informações entre chaves {‘nome da coluna ‘ : ‘novo nome da coluna’ }
inplace=True = para que as alterações já sejam salvas na dataframe do Acre.
O comando rename tem vários parâmetros caso você deseje estudar mais um pouco aí vai o link da biblioteca do pandas a parte específica deste comando.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.rename.html?highlight=rename#pandas.DataFrame.rename
Beleza até aqui, agora vamos alterar em todas as linhas no campo de Estado em vez do nome do estado por extenso vamos colocar a sigla dele.
Mas um comando para nossa listinha.

dfAcre[‘Estado’].replace(‘Acre’,’AC’,inplace=True)
Depois da legenda lá emcima tenho certeza que está todo mundos safo. 😉
Mas Maga cadê o link da biblioteca pandas do comando replace? Né isso que vocês estão falando aí ☺️.
Já está na mão.
Vamos vê como ficou nossa dataframe do Acre com estas alterações.
Agora é arrumar os dados das outras 26 unidades federativas pra deixa tudo no padrão, vou deixa no código tudo mas vamos pular aqui para próxima etapa. Que é … isso mesmo juntar todos os 27 estado em uma dataframe só. Pra isso vamos usar mais um comando do pandas quem adivinha qual será ?
Isso aí todo mundo esperto vamos usar o comando concat.
Aí você como eu, pergunta.
Mas porque o concat é não o join ou o merge ou append?
E sua resposta vai ser sanada com este quadrinho que resume onde utilizar cada um, obrigada quadrinho.🙌 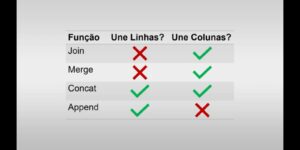
Muito da hora isso, né. Então vamos para o comando.
df_estados = pd.concat([dfAcre,dfAlagoas],axis=0,ignore_index=True)
Legenda:
df_estados = nome que quero da a nova dataframe que vai ter as informações concatenadas.
pd.concat = comando do pandas
[dfAcre,dfAlagoas] = nome das dataframe que vamos junta
axis=0 = o axis faz referência ao eixo que nos vamos junta visto que o concat pergunte juntarmos tanto por linhas quando por colunas o eixo 0 e a linha é o eixo 1 é coluna.
ignore_index=True = este parâmetro é pra que nosso índice não fique com vários números repetidos e sim que ele fique sequencial, como se nada tivesse acontecido.
E lógico vamos da um unique na coluna Estado para vê quantos valores únicos aparece.
df_estados[‘Estado’].unique ()
E mais um link da biblioteca pandas, agora do comando concat.
E tem mais coisas????
O se tem, mas depois de tanto comando novo e as bibliotecas para aprender os parâmetros, vamos da uma paradinha e continua no próximo post , vou ficar te esperando.
Beijos, Maga.😘