
Este projeto tem o objetivo de responder à seguinte pergunta: os indicadores socioeconômicos têm alguma correlação com os índices de transmissibilidade e os percentuais de morte em pacientes de Covid-19?
Será que índices como; maior ou menor nível educacional, renda per capita, densidade demográfica dos entes federativos do Brasil mudam a taxa de contaminação e os casos de obtidos da Covid-19?

Hum… é hora de começar a analisar os dados para sabermos se vamos obter respostas das dúvidas acima.
Para isso vou visualizar alguns dados para verificar quais são as informações que cada dataframe possuí e fazer algumas alterações e interligações usando comandos da nossa biblioteca querida, pandas.
Quais informações eu tenho na base do COVID-19?
Temos região, estado, município, alguns códigos, população TCU2019, casos, obtidos e etc.
Neste post vou abrir o meu csv e vou nomear ele de df1.
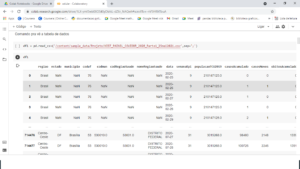
Feito isso, podemos só digitar o nome “df1” e ele vai abrir as portas da esperança e lhe mostra as informações ou você pode usar o comando “Head”, que vai mostra as 5 primeiras linhas do dataframe.
df1.head()

Quero verificar na coluna “estado” quais são os valores únicos dela, pois como vamos usar dois dataframes minha ideia é usar esta coluna como chave de interligação das duas. Então vamos precisar usar o comando “unique” depois de especificar a dataframe e a coluna. Fica assim o comando;
df1[‘estado’].unique

Agora quero ver um conjunto de dados de colunas específicas para verificar como eles estão arrumados.
Então você deve chamar o dataframe e entre colchetes chamas as colunas que deseja.
df1[[‘estado’,’casosAcumulado’,’obitosAcumulado’]]
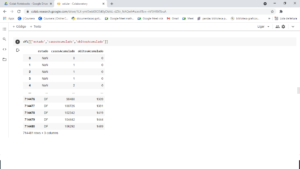
Meu índice está sendo a 1 coluna à esquerda de 0 a infinito, kkkkk, mas isso não me ajuda então vou mudar ele e vou tornar a coluna “estado” como meu índice.
Nossa senhora dos comandos me ajude.
df1.set_index(‘estado’)


Blz e isso que eu quero então agora vamos deixa está alteração permanente no df1 através do implementação do comando “inplace”.
df1.set_index(‘estado’,inplace=True)
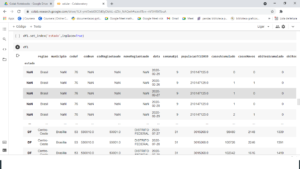
Eu sou meio chatinha, 🤣🤣🤣🤣 e este NaN ( dado não informado) nas primeiras linhas que se referem ao Brasil estão me provocando, logo vamos informar que nestas linhas da coluna “estado” quando aparecer o “NaN” ele troque por “Brasil”, utilizando o “fillna” vamos fazer esta alteração.
df1[‘estado’].fillna(‘Brasil’)

Pronto, neste post eu paro por aqui pois agora vou aprender a concatenar os dados para poder fazer as interligações e aí visualizar os gráficos também.
Te espero no próximo.
Beijos, Maga.😘